Counting words in Python with scikit-learn’s CountVectorizer
Introduction
In a previous article, we used simple techniques to visualize and count words in a document. In this notebook, we will be using another technique. The CountVectorizer from scikit-learn is more elaborate than the Counter tool. It converts a collection of text documents to a matrix of token counts.
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
import numpy as np
The text for our work would be an English version of the Tunisian constitution.
text = open("constitution.txt").read().replace("\n"," ")
Counting words with CountVectorizer
The vectoriser does the implementation that produces a sparse representation of the counts. The fit_transform() method learns the vocabulary dictionary and returns the document-term matrix, as shown below. This method is equivalent to using fit() followed by transform(), but more efficiently implemented.
vectorizer = CountVectorizer()
matrix = vectorizer.fit_transform([text])
matrix # notice the size of the matrix
<1x1741 sparse matrix of type '<class 'numpy.int64'>'
with 1741 stored elements in Compressed Sparse Row format>
The numbers in the array below represent how many times a word showed up in the text.
matrix.toarray()
array([[2, 1, 1, ..., 1, 1, 3]], dtype=int64)
If we want to know which word is which, we can use get_feature_names() to get feature names from feature integer indices. The order of the words in this array matches the order of the numbers from the previous array.
Here, we only output the last 10 words. The last one is youth, and according to the last output value from matrix.toarray(), it appeared 3 times in the text. The word younger appeared just once!
print (vectorizer.get_feature_names()[1731:])
['works', 'world', 'worship', 'writing', 'written', 'year', 'years', 'young', 'younger', 'youth']
We can use DataFrames to turn the results into a human-readable format.
counts_df = pd.DataFrame(matrix.toarray(), columns = vectorizer.get_feature_names())
counts_df

Even more, we can get a sorted list similar to the result given by Counter. We use some pandas magic to transpose index and columns, and the result is naturally a transposed DataFrame. In fact, the used property T is an accessor to the method transpose().
counts_df.T.sort_values(by=0, ascending=False).head(8)

As seen so far, the CountVectorizer is quite useful, and it can handle a lot of preprocessing for us. That would allow us to focus on the interpretation of data for example.
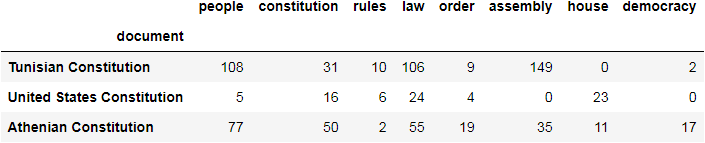
So, how many times did people appear in the text?
counts_df['people']
0 108
Name: people, dtype: int64
How about law and order?
print (counts_df['law'], '\n' ,counts_df['order'])
0 106
Name: law, dtype: int64
0 9
Name: order, dtype: int64
Counting words in multiple documents
All of that is quite good and exciting. Now, we will see how is CountVectorizer with multiple text documents.
We will be using the United States’ Constitution and the Athenian Constitution, by Aristotle in addition to our previous text.
To read a text file from a URL in Python, we make a request with Requests module to get a Response object. We can read the content of the server’s response by accessing .text.
import requests
US_constitution = requests.get("https://www.gutenberg.org/cache/epub/5/pg5.txt").text[2623:] # To slice out the unwanted text
Athenian_constitution = requests.get("https://www.gutenberg.org/cache/epub/26095/pg26095.txt").text[610:]
We construct a DataFrame with the content by passing the appropriate data.
df = pd.DataFrame([
{ "document": "Tunisian Constitution", "content": text},
{ "document": "United States Constitution", "content": US_constitution },
{ "document": "Athenian Constitution", "content": Athenian_constitution },])
df

Finally, we create an organized DataFrame of the words counted in each document. This time, we feed the entire content column the CountVectorizer instead of a single text variable.
vectorizer = CountVectorizer()
matrix = vectorizer.fit_transform(df.content)
counts = pd.DataFrame(matrix.toarray(), index = df.document, columns = vectorizer.get_feature_names())
counts

This is a nice feature where we can select serveral interesting words to check in all documents.
counts[['people','constitution', 'rules', 'law', 'order', 'assembly', 'house', 'democracy']]
In this notebook, we used CountVectorizer from sklearn to count words in multiple documents. It is more advanced than working with Counter and having to do all the text cleaning.
Leave a comment